Comment Faire Une Descente De Gradient Avec Une Fonction Softmax
Alors, on papote descente de gradient et softmax ? C'est un peu le dessert après un gros plat de maths, mais promis, on va rendre ça digeste ! Imagine que tu dois grimper une montagne (de coût, tu vois le genre?) et ton but, c'est d'arriver en bas, au point le plus bas possible. La descente de gradient, c'est ta technique de rando !
Softmax, Kézako?
Avant de se lancer dans la descente proprement dite, faut qu'on cause softmax. C'est une fonction, ni plus ni moins, qui transforme un paquet de nombres (tes scores, genre "chat : 2.5, chien : 1.2, hamster : 0.8") en probabilités. C'est-à-dire, des nombres entre 0 et 1 qui, additionnés, font 1. Magique, non ? Du coup, on a une vraie distribution de probabilité. Par exemple, "chat : 0.7, chien : 0.2, hamster : 0.1". Bingo ! On a une idée claire de ce que notre modèle pense être la bonne réponse.
Pourquoi softmax ? Ben, c'est hyper pratique pour la classification. On a plein de classes possibles (chat, chien, hamster… la ménagerie, quoi !) et softmax nous dit quelle est la probabilité que notre image appartienne à chacune de ces classes. Génial pour les réseaux de neurones !
Must Read
La Descente, Enfin !
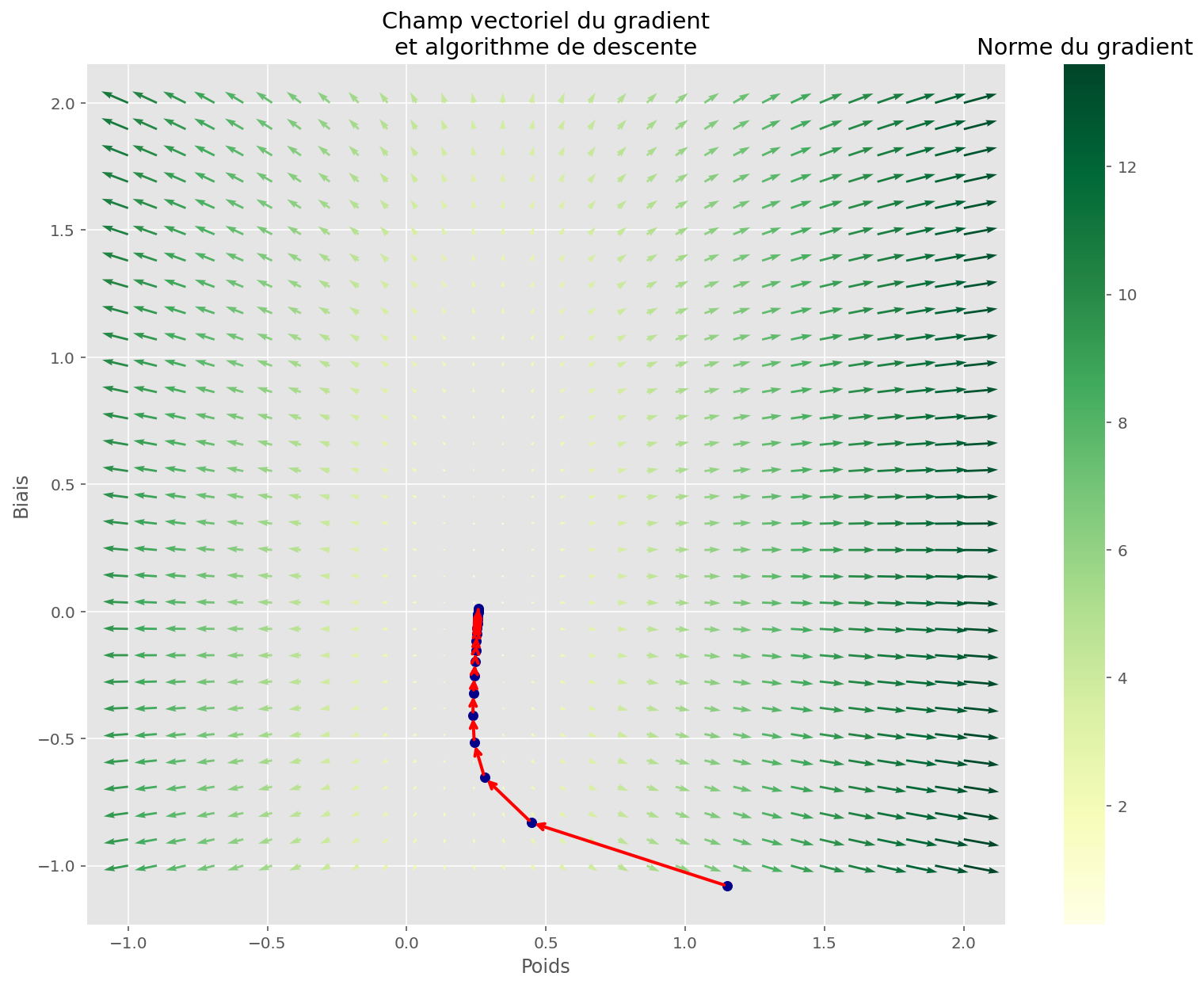
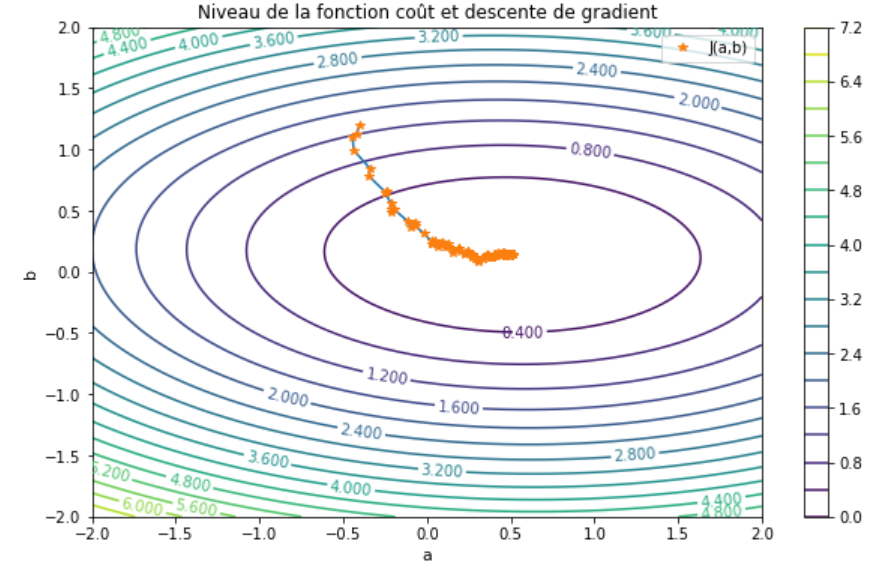
Maintenant, on y est. La descente de gradient. On a notre fonction softmax qui crache des probabilités, on compare ça à la réalité (par exemple, l'image était vraiment un chat), et on calcule une "erreur" (le coût). Et là, c'est le moment de réajuster les paramètres de notre modèle.
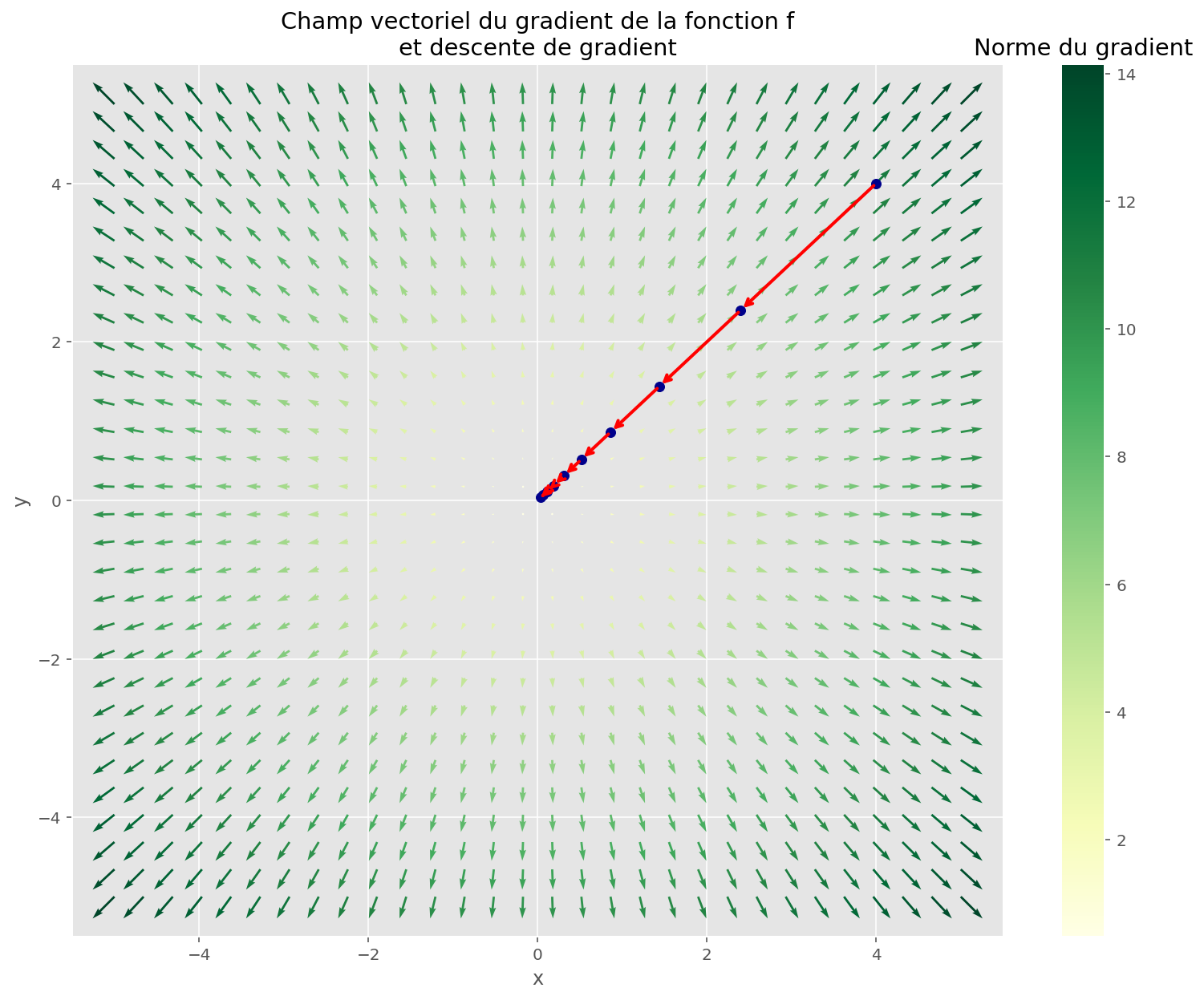
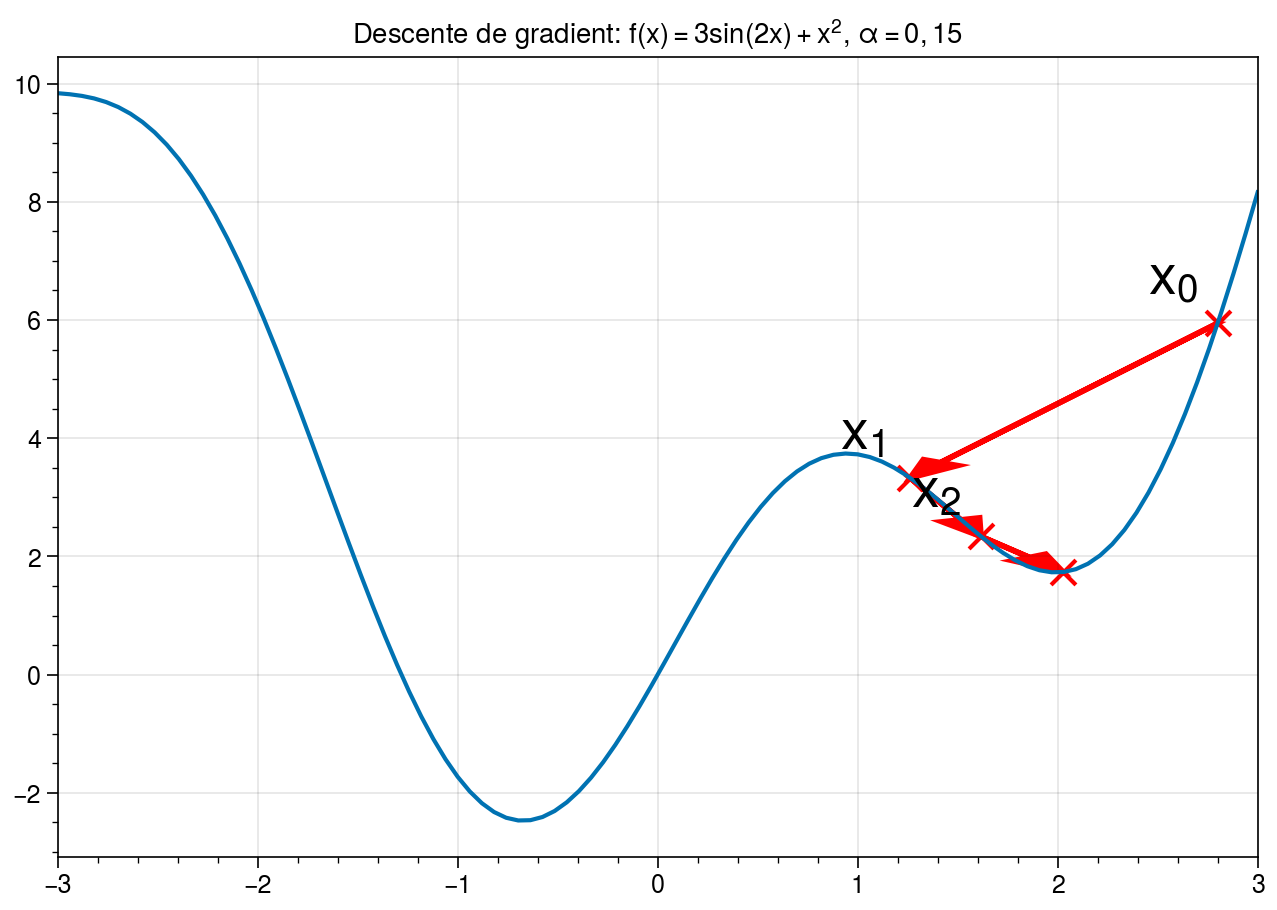
L'idée, c'est de calculer le gradient de cette erreur par rapport à ces paramètres. Le gradient, c'est une flèche qui nous indique dans quelle direction il faut bouger nos paramètres pour que l'erreur diminue. C'est un peu comme si un GPS nous disait : "Tourne à gauche, ça descend !" Super important : on bouge dans la direction opposée au gradient. D'où le nom "descente" !
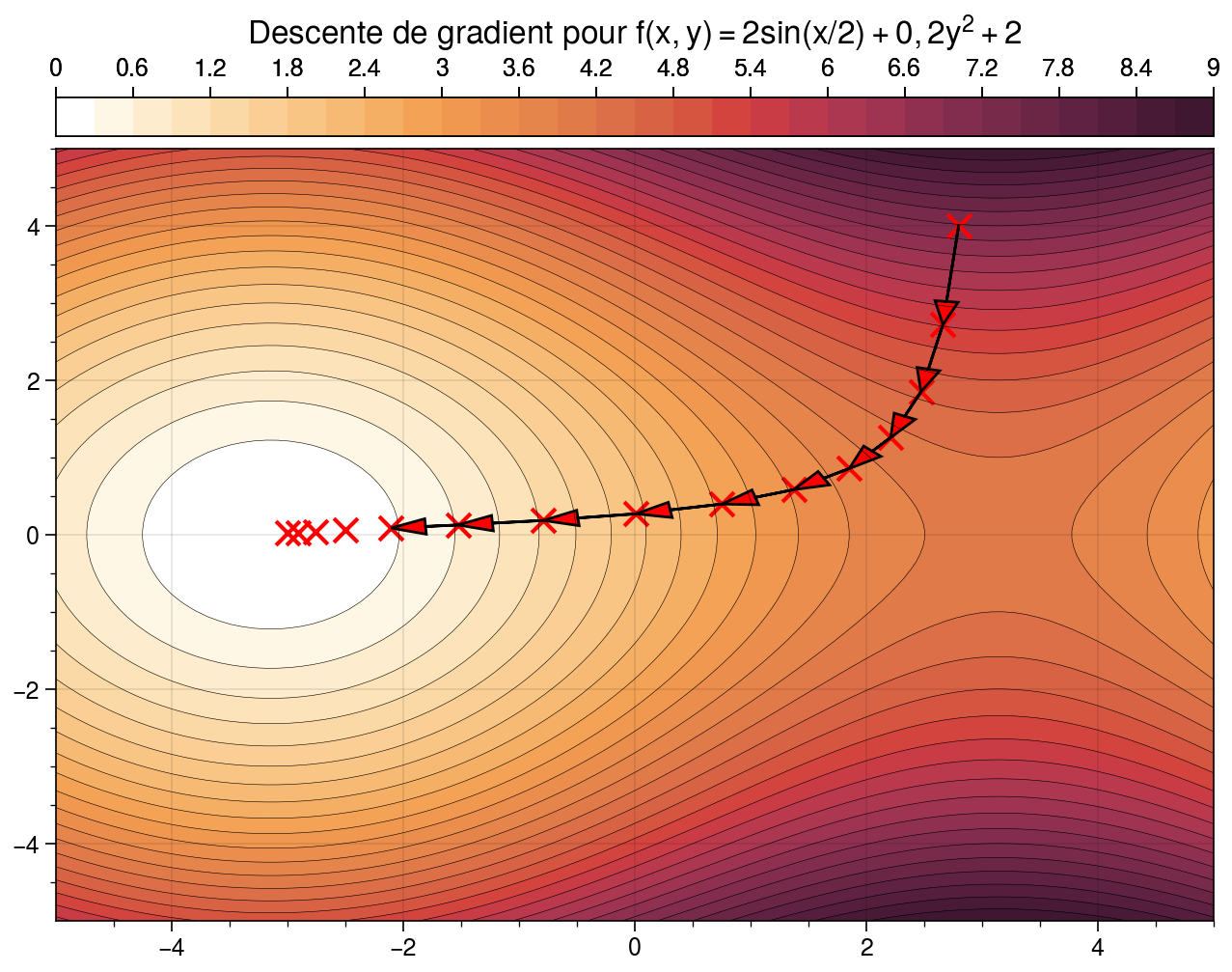
Comment ça Marche Concrètement?
On prend nos paramètres actuels, on calcule le gradient, et on les met à jour en soustrayant (ou en ajoutant, vu qu'on va dans la direction opposée) ce gradient, multiplié par un petit nombre, appelé "taux d'apprentissage". Ce taux, c'est la taille des pas qu'on fait pendant notre rando. Trop grand, on risque de sauter par-dessus le minimum et de se retrouver de l'autre côté de la vallée. Trop petit, on mettra une plombe à arriver en bas. Faut trouver le juste milieu!
Et on répète ça plein de fois. On recalcule les probabilités avec la softmax, on calcule l'erreur, on calcule le gradient, on met à jour les paramètres... Et, petit à petit, notre modèle devient de plus en plus précis. C'est un peu comme affiner une recette de cuisine. On ajuste les ingrédients jusqu'à obtenir le plat parfait !
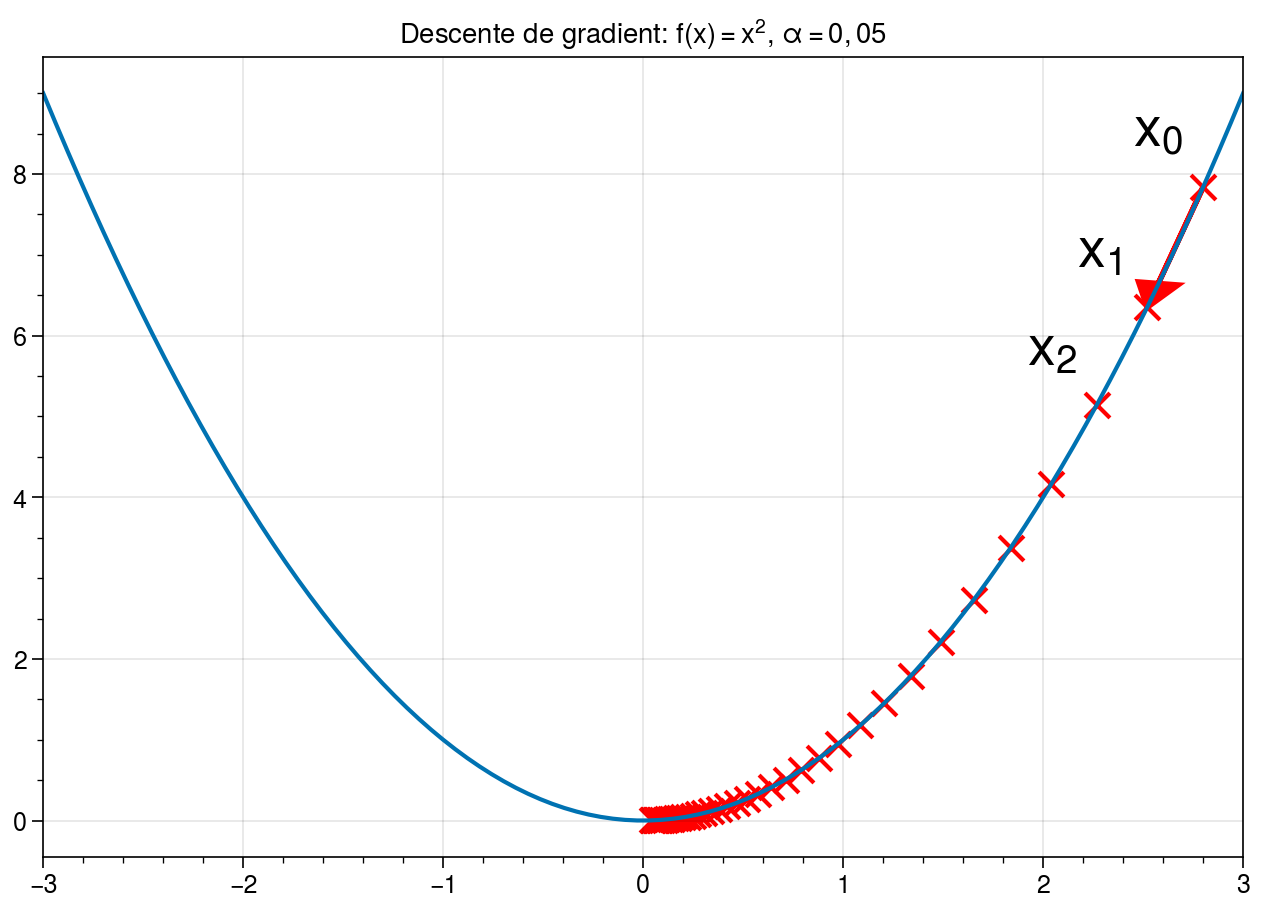
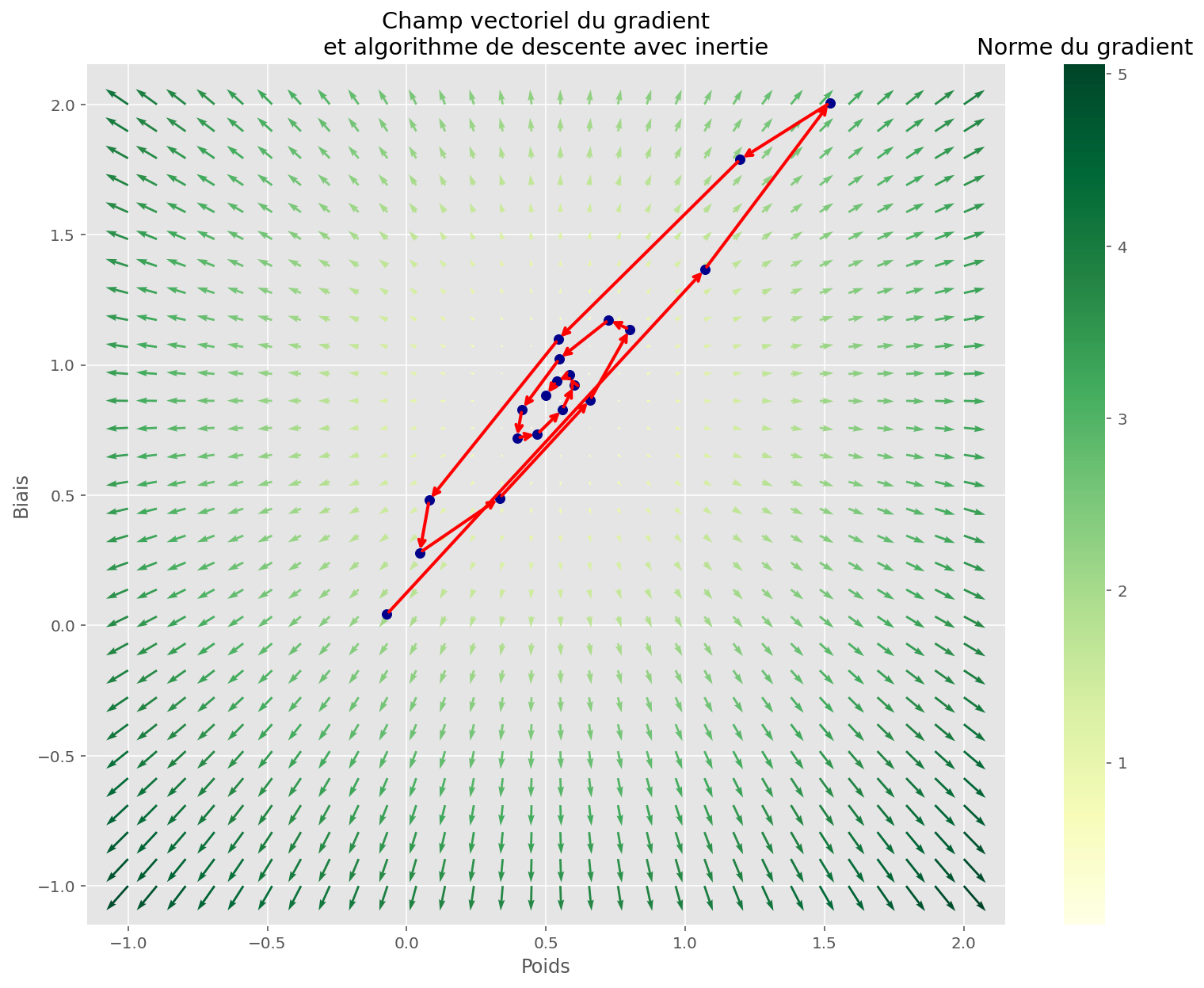
Bien sûr, y'a plein de subtilités (momentum, Adam, etc.), mais la base, c'est ça. Softmax qui transforme les scores en probabilités, et descente de gradient qui ajuste les paramètres pour minimiser l'erreur. Facile, non ? (Bon, peut-être pas si facile, mais on a fait le tour, l'essentiel est là!)
Voilà, voilà ! On a survécu à la descente de gradient et à la softmax. On peut enfin savourer notre café! 😉